重消化-Transformers Explained Visually (Part 3): Multi-head Attention, deep dive
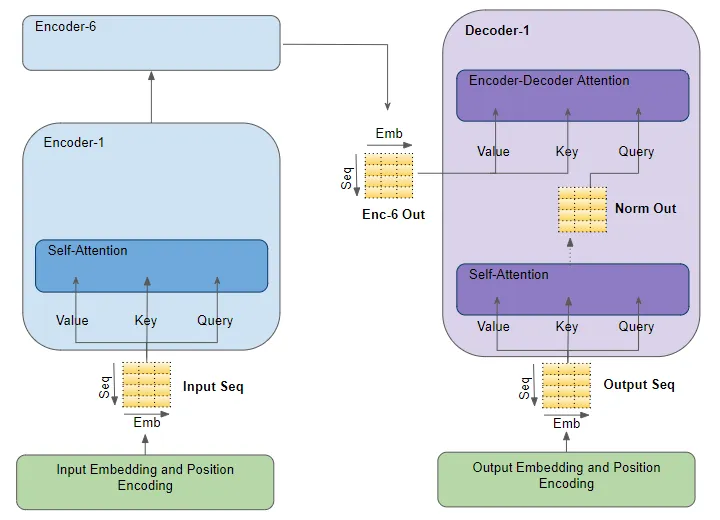
how attention is used in the transformer
attention input parameters - Query, Key, Value
attention layer有三个输入参数,分别为Query, Key, Value。所有三个参数在结构上都很相似,序列中的每个单词都由一个向量表示。
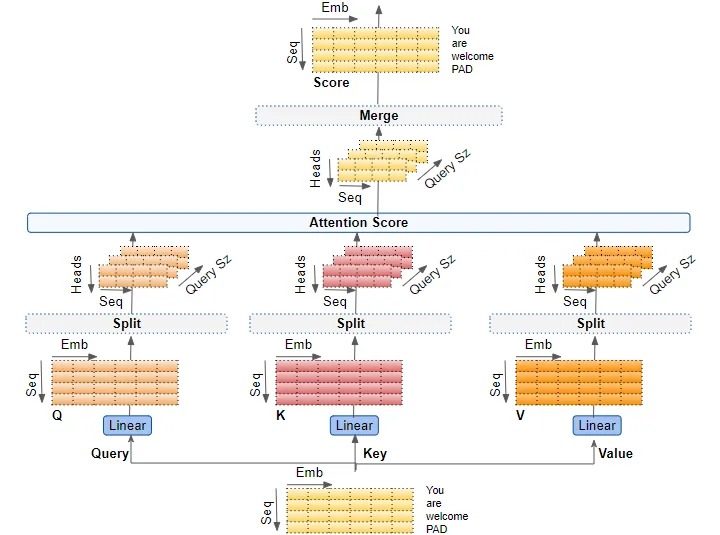
Multiple Attention Heads
attention modules并行地多次重复计算。每个部件称为一个attention head。每个attention modules将它的Query, key 和 value分为N份,将每份独立地发给head。所有的这种类似的attention 计算组合在一起产生最终的attention score。这被称为multi-head attention,它赋予 Transformer 更大的能力来编码每个单词的多种关系和细微差别。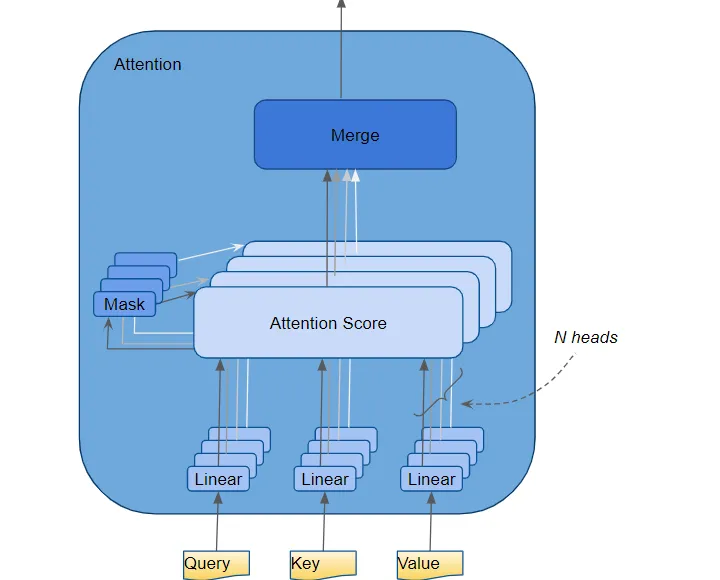
Attention Hyperparameters
- embedding size。 embedding vector的size
- query size(等同于key and value size)。三个线性层分别用于生成Query、Key和Value矩阵的权重size.
- number of attention heads.
Input layers
The Input Embedding and Position Encoding layers 生成一个size为(batch size, sequence length, embedding size)的张量,这会被喂给第一个encoder的Query、Key和Value。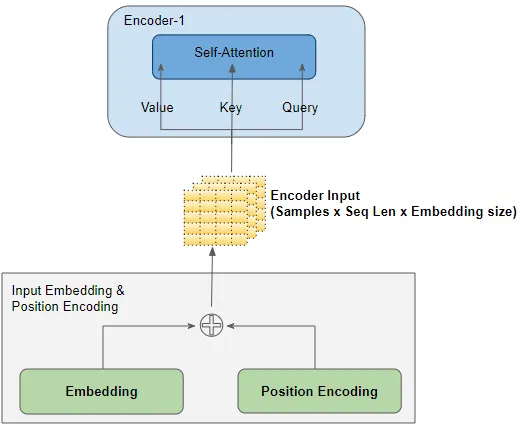
为了简化说明,本文设置batch size为1.
linear layers
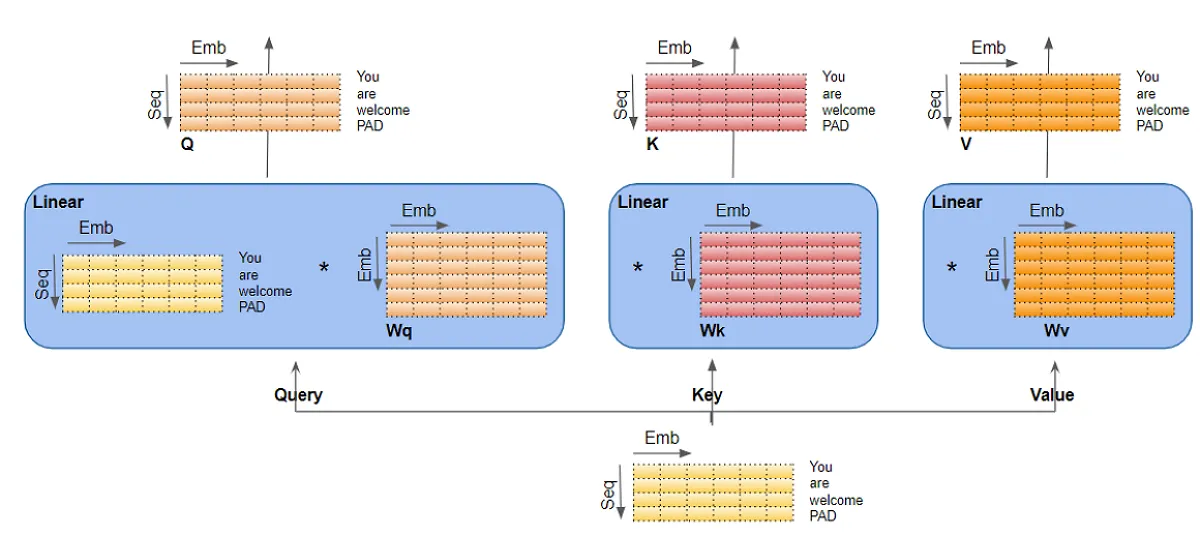
Query、Key和Value有三个独立的线性层。每个线性层都有自己的权重。输入通过这些线性层来生成 Q、K 和 V 矩阵。
splitting data across attention heads
数据被分割到多个attention head中,以便每个attention head都可以独立处理。
然而,需要理解的重要一点是,这只是逻辑上的分割。 Query、Key 和 Value 在物理上并未分割成单独的矩阵,每个分割矩阵对应一个attention head。单个数据矩阵分别用于Query、Key 和 Value ,每个attention head具有逻辑上独立的矩阵部分。类似地,也不存在单独的linear layer,每个attention head都有一个linear layer。所有attention head共享相同的linear layer,但只是对数据矩阵的“自己”逻辑部分进行操作。
linear layer weights are logically partitioned per head
这种逻辑分割是通过在attention head上均匀地划分输入数据和线性权重来完成的。我们可以选择通过query size来实现这个

因此所有的head的计算可以通过单个矩阵运算来实现,而不需要N个独立运算,这使得计算更加高效。
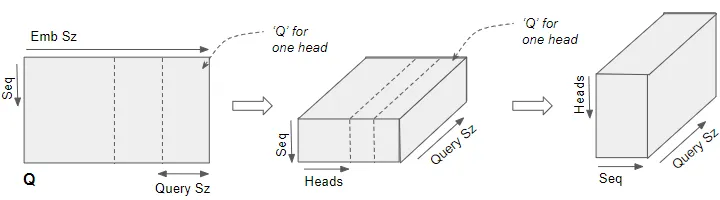
reshaping the Q,K and V matrices
通过linear layers产生的Q, K, V矩阵被reshaped,并且添加了一个显式的head dimention。想象成每个head将本来是完整的矩阵切分成了N个小矩阵。
原始的Q(batch size$\times$ sequence dimension $\times$ embedding size )先reshape为形状为(batch size$\times$ sequence dimension $\times$ head number $\times$ query size),然后再进行swap得到(batch size$\times$ head number $\times$ sequence dimension $\times$ query size)。
先reshape再swap的原因是:这跟数据的底层存放有关系
下图是一个将Q matrix分割到若个head的过程。请注意:这只是一个逻辑上的过程,她还是一个单独的矩阵。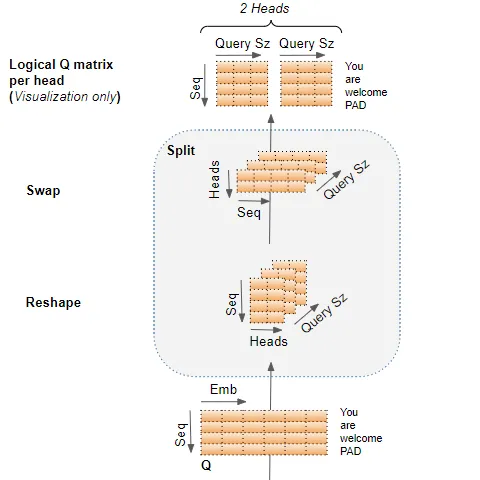
compute the attention score for each head
以batch中只有一个样本,只有一个head为例进行说明。
encoder self-attention score
完整计算encoder self-attention中attention score过程如下。
其中mask value用于mask out the padding values。
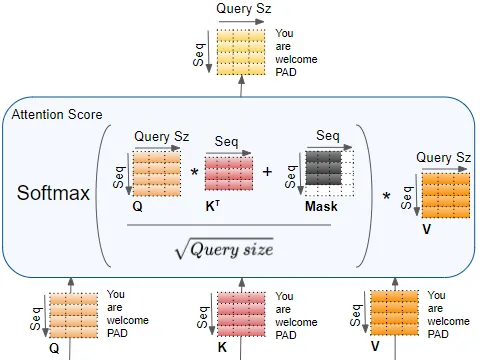
computes the interaction between each input word with other input words
decoder self-attention score
The Decoder Self-Attention works just like the Encoder Self-Attention, except that it operates on each word of the target sequence.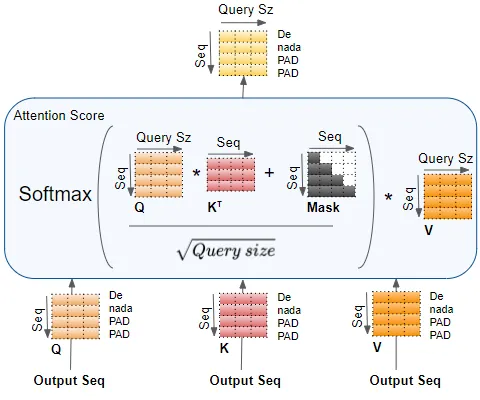
computes the interaction between each target word with other target words
Decoder Encoder-Decoder Attention score
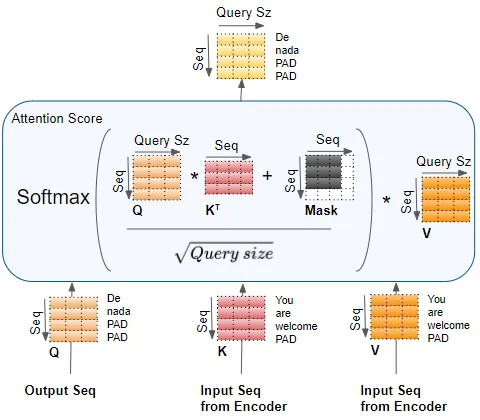
computes the interaction between each target word with each input word
merge each head’s attention scores together
这是通过简单地重塑结果矩阵以消除头部维度来完成的。步骤是:
- 交换head和sequence dimensions的维度来reshape attention score matrix,从(batch, head, sequence,query size)变为(batch, sequence, head, query size)
- 通过重塑为(batch, sequence, head $\times$ query size)来折叠头维度。这有效地将每个头的注意力分数向量连接成单个合并的注意力分数
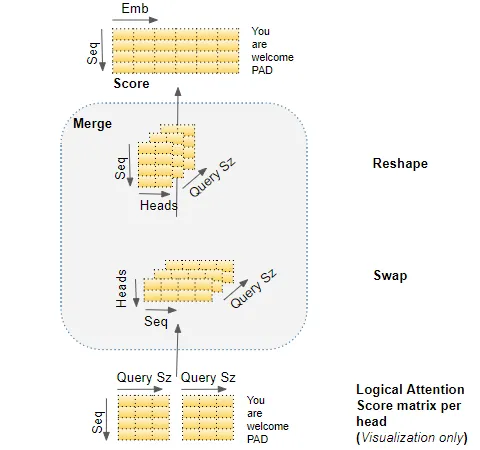
因为 Embedding size =Head * Query size,merged score变为(batch, sequence, embedding size)
multi-head attention 的完整计算过程
multi-head split captures richer interpretations
embedding vectors 在逻辑上分给多个head的意义是:embedding的不同部分可以学习每个单词含义的不同方面,因为她与sequence中的其他单词相关,这使得transformer能够捕获更丰富的sequence解释。