重消化-Transformers Explained Visually (Part 2): How it works, step-by-step
architecture overview
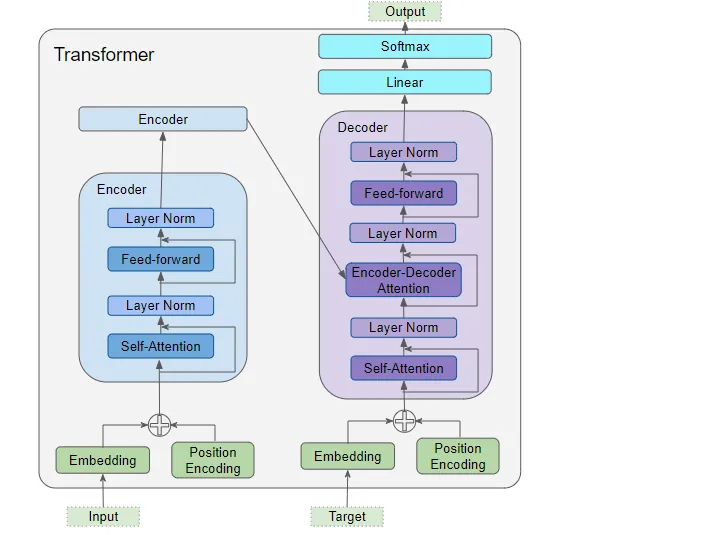
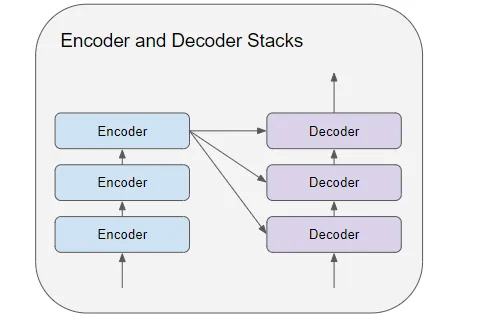
以上是只包含一个encoder和一个decoder的最简单的transformer。
- 输入数据(encoder和decoder都有)
- embedding layer
- position encoding layer
- encoder
- encoder stack包含一组encoders
- multi-head attention layer
- feed-forward layer
- decoder
- decoder stack包含一组decoders
- 2个multi-head attention layers
- feed-forward layer
- 输出数据
- linear layer
- softmax layer
接下来按照transformer的训练过程来说明其工作过程。
embedding and position encoding
每个word都应该输入这个词的meaning和在语句中的position.
- embedding layer encodes 单词的意思
- position encoding layer 表示 单词的位置
embedding
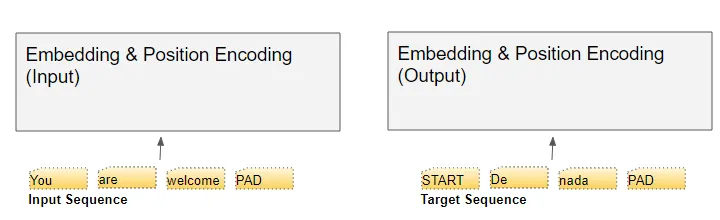
transformer包含两个embedding layers,输入和输出数据都需要喂给embedding layers,但是target sequence在喂之前需要在最前面插入一个start token。
在inference过程中,由于没有target sequence,因此此时喂给output的embedding layer的是一个单纯的start token
文本序列根据vocabulary映射到word IDs,embedding layer将每个单词映射到一个embedding vector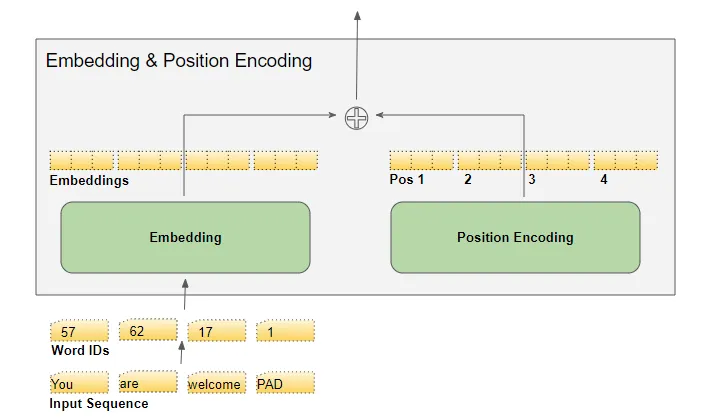
position encoding
transformerde的输入文本中的所有单词都是并行输入的,因此必须添加position信息。
同样也有两个position encoding layers。但是position encoding独立于input sequence计算,是一组固定的值,且只取决于sequence的最大长度。
- the first item is a constant code that indicates the first position
- the second item is a constant code that indicates the second position,
- and so on.
这些值的计算公式如下:
matrix dimension
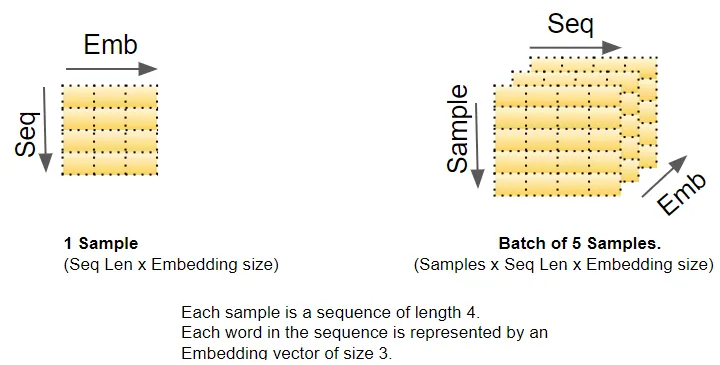
the embedding and position encoding layers操作一系列sequence samples表示的矩阵。embedding layer将每个word ID编码为一个word vector,其长度为embedding size,从而产生一个(samples, sequence length, embedding size)形状的矩阵。position encoding使用和embedding size一样的encoding size。因此他产生了一个形状相似的矩阵,可以加入embedding matrix中。
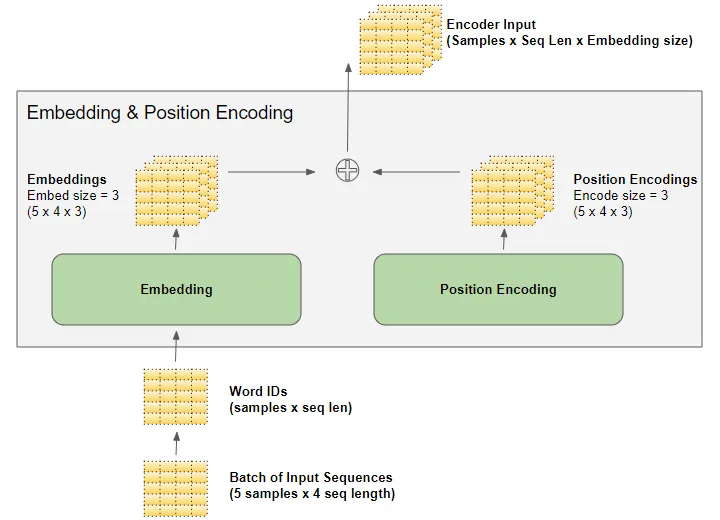
当数据流经encoder和decoder stack时,embedding and position encoding layers生成的(samples, sequence length, embedding size)形状在整个 Transformer 中得到保留,直到由最终输出层重新整形。
encoder
第一个encoder从embedding和position encoding中获取其输入,其他的encoder是从他之前的那个encoder获得输入。
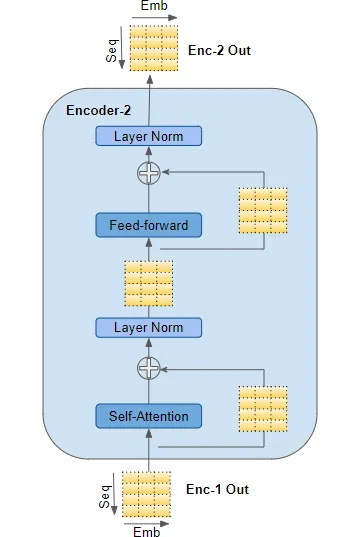
上图是encoder的内部结构,self-attention和feed-forward sub-layers都有一个residual skip-connection,在layer-normalization之后。
decoder
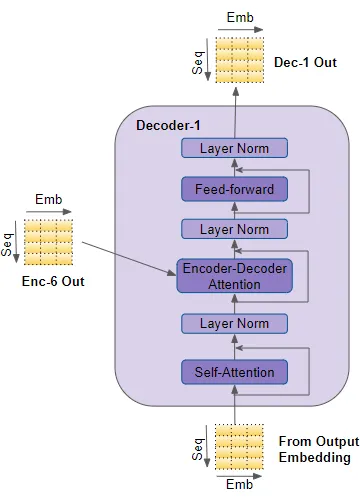
decoder和encoder的结构相似,有几处不同。
decoder将其输入传递到multi-head self-attention layer。它的运行方式与encoder中的运行方式略有不同。只允许参与sequence中earlier position。这是通过masking future position来完成的,我们很快就会讨论这一点。
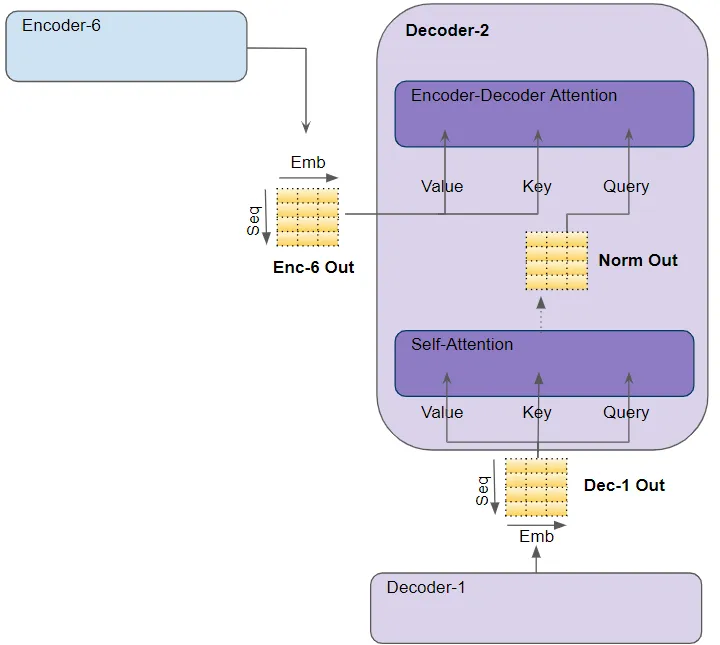
decoder还有第二个multi-head self-attention layer,被称为 encoder-decoder attention layer这个layer的数据来源分为前一个self-attention以及encoder stack的输出。
self-attention、Encoder-Decoder attention和feed-forward sub-layers都有一个residual skip-connection,在layer-normalization之后。
attention
在transformer中,一共有三处用到了attention。encoder中的self-attention,以及decoder中的self-attention和encoder-decoder attention.
attention的输入参数为(query, key, value):
- encoder self-attention: (query, key, value)
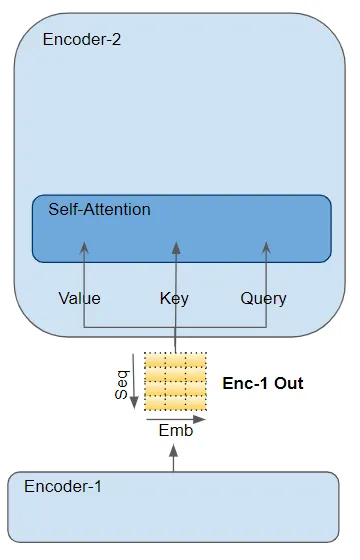
- decoder self-attention: (query, key, value)
- decoder encoder-decoder attention: 来自最后一个encoder的输出传递(value, key),下面的 Self-attention(和 Layer Norm)模块的输出被传递给 Query 参数.
multi-attention
transformer将每个attention processor称为一个attention head并且并行地执行多次attention,这就是multi-attention.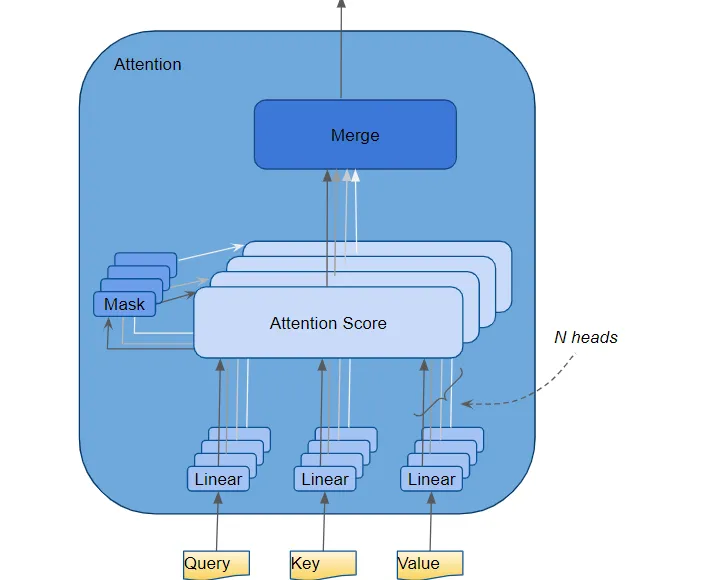
Query, key, value分别通过各自的linear layer,每个layer有自己的权重,产生三个结果称为Q,K,V,使用如下的attention公式来产生attention score。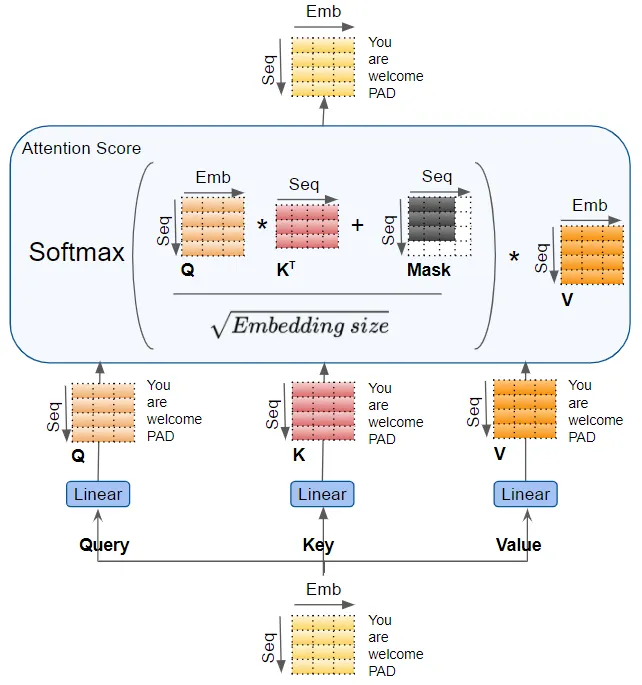
Q,K,V values包含了每个词汇的encoded representation,在注意力计算过程中,将每个单词与序列中其他单词结合,以便attention score对每个单词的score进行编码。
attention masks
计算注意力分数时, masking应用于 计算Softmax 之前的的分子。被屏蔽的元素(白色方块)被设置为负无穷大,以便 Softmax 将这些值变为零。
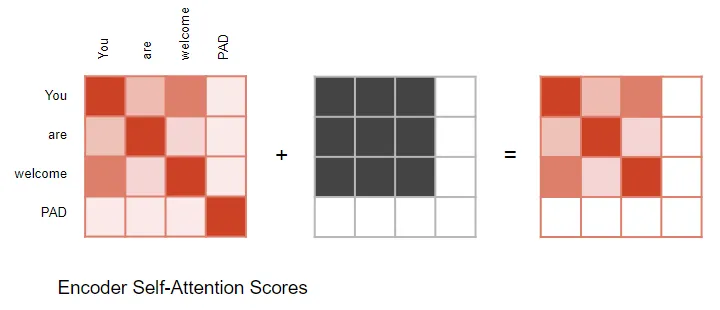
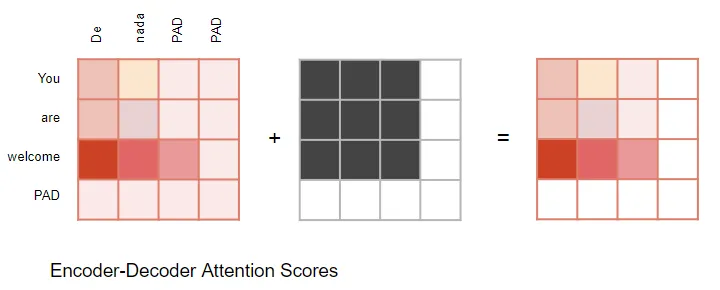
in the encoder self-attention and in the encoder-decoder-attention
masking用于在输入句子中有填充的情况下将注意力输出为零,以确保填充不会对自注意力产生影响。 (注意:由于输入序列可能具有不同的长度,因此它们像大多数 NLP 应用程序中一样使用填充标记进行扩展,以便可以将固定长度的向量输入到 Transformer。)
in the decoder self-attention
masking用于防止decoder在预测下一个单词时‘偷看’ target sequence的剩余部分
decoder处理input sequence中的单词并使用它们来预测target sequence中的单词。在训练期间,这是通过 Teacher Forcing 完成的,其中完整的target sequence作为decoder输入提供。因此,在预测某个位置处的单词时,decoder可以使用该单词之前的目标单词以及该单词之后的目标单词。这允许decoder通过使用未来“时间步骤”中的目标词来“作弊”。
例如在预测 word3时,decoder只能根据Mi nimbere es来预测,不可以使用Ketan。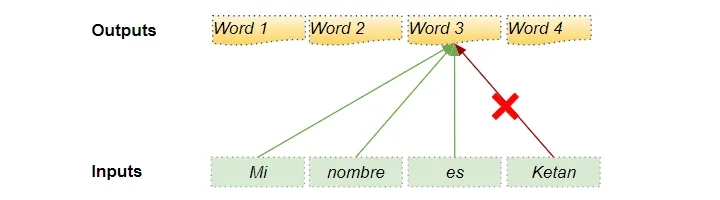
decoder会屏蔽本次单词之后的单词。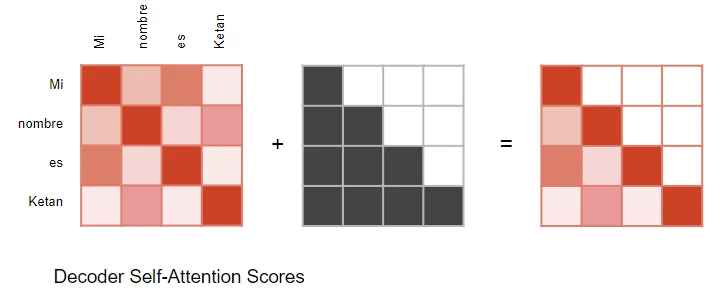
generate output
decoder stack中的最后一个decoder将其输出传给output component,这个部件将输出转换成句子。
linear layer将decoder vector投影到word score中,其中目标词汇表中每个唯一单词在句子中的每个位置都有一个分数值。例如,如果我们的最终输出句子有 7 个单词,而目标西班牙语词汇有 10000 个唯一单词,我们会为这 7 个单词中的每个单词生成 10000 个分值。分值表示词汇表中每个单词在句子的该位置出现的可能性。
然后,Softmax 层将这些分数转换为概率(加起来为 1.0)。在每个位置,我们找到概率最高的单词的索引,然后将该索引映射到词汇表中相应的单词。然后这些单词形成 Transformer 的输出序列。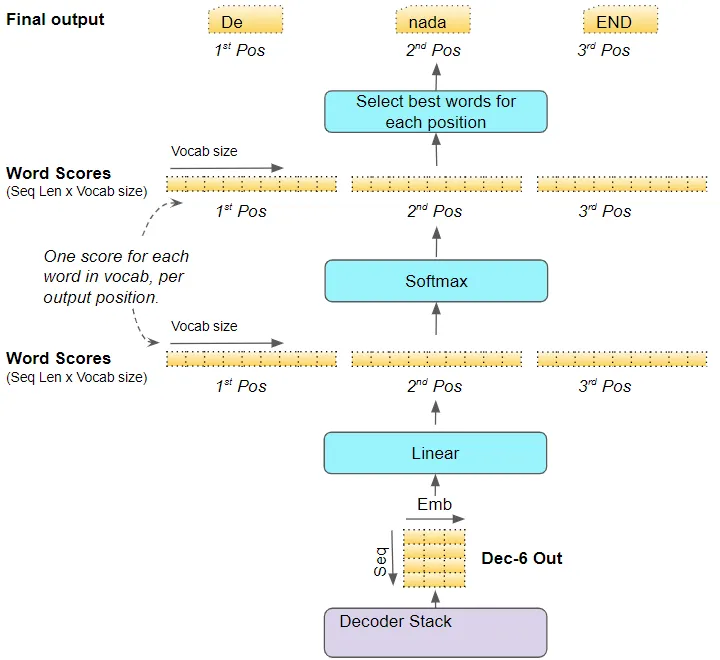
training and loss function
在训练过程中,我们使用交叉熵损失等损失函数来将生成的输出概率分布与目标序列进行比较。概率分布给出了每个单词出现在该位置的概率。
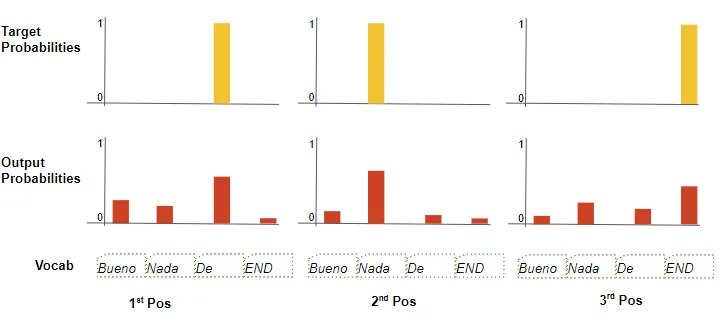
假设我们的目标词汇只包含四个单词。我们的目标是产生与我们预期的目标序列“De nada END”相匹配的概率分布。
这意味着第一个单词位置的概率分布对于“De”来说应该是 1,而词汇表中所有其他单词的概率应该是 0。类似地,“nada”和“END”对于“De”来说应该有 1 的概率。分别是第二个和第三个词的位置。
与往常一样,损失用于计算梯度,以通过反向传播训练 Transformer。