重消化-Transformers Explained Visually (Part 1): Overview of Functionality
what is a transformer
transformer在处理连续文本时特别有用,他将输入的文本序列处理并输出成另一文本序列。它包含了a stack of encoder layers and decomder layers.
The encoder stack and decoder stack 都拥有自己对应的embedding layers for their respective inputs. 最终还有一个output layer来生成最终的输出。
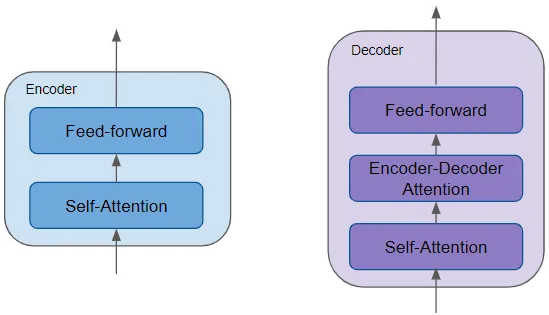
- 所有的encoders都相同,decoder也一样。encoder中包含最重要的self-attention (用于计算序列中不同单词之间的关系)以及前馈层。
- decoder包含self-attention layer, feed-forward layer以及encoder-decoder attention layer.
- 每个encoder和decoder有自己的权重。
encoder是一个可重用的模块,除了上述的两层之外,他还在两层之间存在residual skip connections以及layerNorm layers。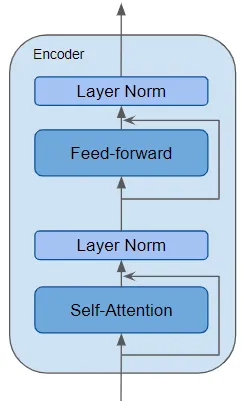
transformer有许多变体,有些根本没有decoder。
what does attention do
transformer突破性能的关键在于他对注意力的使用。在处理词汇时,attention会关注于输入中与该词联系紧密的词。例如”ball”会关联到holding和blue,而boy并不会关联到blue。
transformer架构通过将输入序列中的每个单词与其他单词相关联来使用self-attention
Consider two sentences:
- The _cat_ drank the milk because it was hungry.
- The cat drank the _milk_ because it was sweet.

在第一句话中,“it”一词指的是“猫”,而在第二句话中,“it”一词指的是“牛奶”。当模型处理“it”这个词时,自注意力会为模型提供更多有关其含义的信息,以便模型可以将“it”与正确的单词关联起来。
为了使其能够处理句子意图和语义的更多细微区别,transformers为每个单词提供了多个attention scores。例如。在处理“it”一词时,第一个分数突出显示“cat”,而第二个分数突出显示“hungry”。因此,当它解码“it”这个词时,例如,通过将其翻译成另一种语言,它会将“cat”和“hungry”的某些方面合并到翻译的单词中。

training
训练数据包含两个部分:
- 源或输入序列(例如,英语中的“You are welcome”,用于解决翻译问题)
- 目的地或目标序列(例如西班牙语中的“De nada”)
Transformer traning 的目标是学习如何通过使用输入和目标序列来输出目标序列。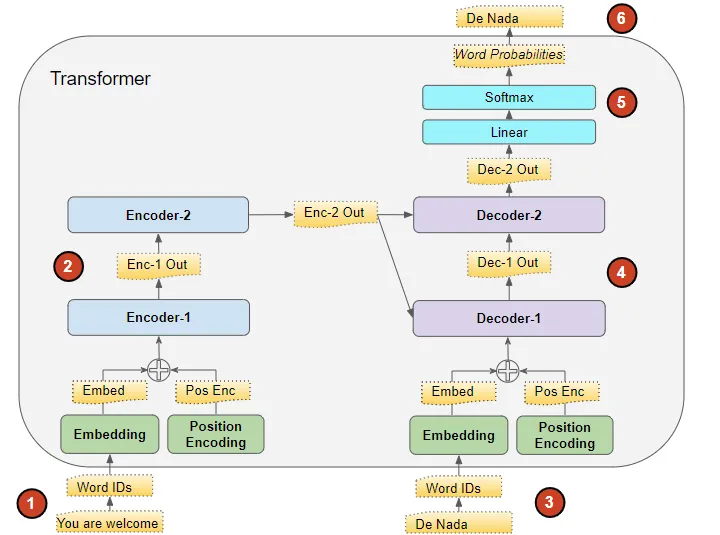
- input sequence 被转换为embeddings (with position encoding),喂给encoder。
- encoder stack运行这两数据,并产生这个输入序列的encoded representation。
- target sequence 前面添加了 start-of-sentence token(句子开头标记),然后被转换为embeddings (with position encoding),喂给decoder。
- decoder stack结合encoder stack的encoded representation来处理这两个数据,并产生target sequence 的 encoder representation。
- output layer将encoder representation转换为词概率 word probabilities以及最终的输出序列。
- Transformer 的损失函数将此输出序列与训练数据中的目标序列进行比较。该损失用于生成梯度,以在反向传播期间训练 Transformer。
inference
在推理期间,我们只有输入序列。
Transformer inference 的目标是仅从输入序列生成目标序列。
就像在 Seq2Seq 模型中一样,我们在循环中生成输出,并将前一个时间步的输出序列馈送到下一个时间步的解码器,直到遇到句末标记。与 Seq2Seq 模型的区别在于,在每个时间步,我们重新输入迄今为止生成的整个输出序列,而不仅仅是最后一个单词。
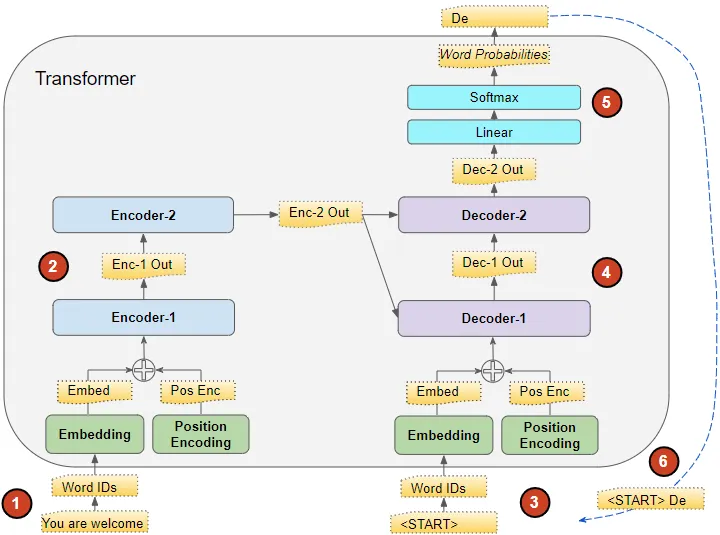
- input sequence 被转换为embeddings (with position encoding),喂给encoder。
- encoder stack运行这两数据,并产生这个输入序列的encoded representation。
- 由于没有目标序列,我们使用空的序列(只包含a start-of-sentence token)然后被转换为embeddings (with position encoding),喂给decoder。
- decoder stack结合encoder stack的encoded representation来处理这两个数据,并产生target sequence 的 encoder representation。
- output layer将encoder representation转换为词概率 word probabilities以及最终的输出序列。
- 我们将输出序列的最后一个单词作为预测单词。该单词现在填充到decoder输入序列的第二个位置,其中现在包含句子开头标记和第一个单词.
- 返回步骤#3。和以前一样,将新的decoder sequence输入到模型中。然后取出输出的第二个字并将其附加到decoder sequence中。重复此操作,直到预测出句末标记。请注意,由于每次迭代的编码器序列都不会改变,因此我们不必每次都重复步骤 #1 和 #2。
teacher forcing
在training期间,将target sequence喂给decoder称为teacher forcing
what are transformers used for
transformer的用途很广泛,可用于大多数NLP任务。对于不同的问题,transformers架构有不同的风格。基本的encoder layer作为构建的常用部件,根据要解决的问题具有不同的特定于应用程序的”head”.
transformer classification architecture
以sentiment analysis应用为例,将文本文档作为输入,一个classification head获取transformer的输出,并且生成分类标签的预测,例如消极和积极情绪。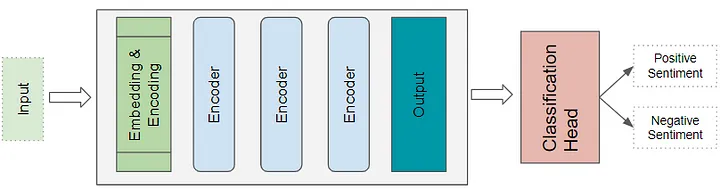
Transformer Language Model architecture
语言模型架构将输入序列的初始部分(例如文本句子)作为输入,并通过预测随后的句子来生成新文本。A Language Model head 获取 Transformer 的输出并生成词汇表中每个单词的概率。概率最高的单词成为句子中下一个单词的预测输出。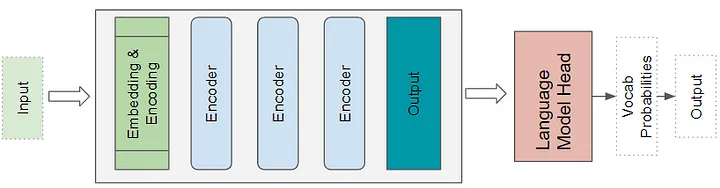
how are they better than RNNs
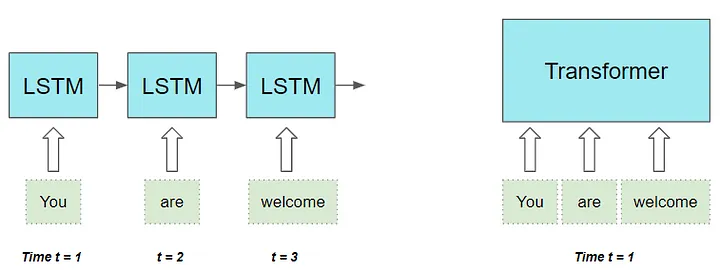
RNNs以及近似 LSTMs和GRUs都可以用来处理NLP任务,RNN-based seq2seq models性能很好,但是他们有两个限制:
- 很难长句子中的单词之间的long-range依赖
- 一次一词地顺序处理序列,因此只能顺序执行计算,即必须做完t-1时间步才能做t时间步
另一方面,对于所有输出可以并行执行的CNNs而言,虽然剪辑速度更快,但是在处理远程依赖方面也有局限性
- 在卷积层中,只有足够接近以适应内核大小的图像部分(或单词,如果应用于文本数据)可以相互交互。对于相距较远的项目,需要一个更深层次的多层网络。
transformer处理了以上的限制,
- 可以并行计算序列中的所有词汇
- 不在乎单词之间的距离,它同样擅长计算相邻单词和相距较远的单词之间的依赖关系。