inline ptx assembly in CUDA
asm()提供了一种将PTX代码插入CUDA的一种方法,形式为1
asm("membar.gl;");
parameters
asm的基本语法为1
asm("template-string" : "constraint"(output) : "constraint"(input));
其中可以有多个’input’输入’output’输出,使用逗号隔开。’template-string’表示用于表明操作的PTX指令,多个ptx指令用分号隔开。
通常一条指令包括两方面的内容: 操作码和操作数,操作码决定要完成的操作,操作数指参加运算的数据及其所在的单元地址。
例如1
asm("add.s32 %0, %1, %2;" : "=r"(i):"r"(j),"r"(k));
template-string中的每个%n表示后面的操作数的顺序,%0是第一个操作数,%1是第二个操作数以此类推。输出操作数总是在输入操作数的前面。这个例子等价于1
add.s32 i,j,k
注意,string中的%n的顺序是可变的,上面的指令也可以写成1
asm("add.s32 %0, %2, %1;":"=r"(i):"r"(k),"r"(j));
%n也可以重复1
asm("add.s32 %0,%1,%1;":"=r"(i):"r"(k));
如果这里没有输入操作数,可以舍去最后的冒号1
asm("mov.s32 %0, 2;":"=r"(i));
如果这里没有输出操作数,可以连接两个冒号1
asm("mov.s32 r1, %0;"::"r"(i));
如果想要在PTX中使用%,需要使用两个%来进行转义1
asm("mov.s32 %0, %%clock;":"=r"(x));
操作数值通过约束指定的任何机制传递。这里的rconstraint表示32bit的整型寄存器1
asm("add.s32 %0,%1,%2;":"=r"(i):"r"(j),"r"(k));
会产生下列的代码(通过编译器生成)1
2
3
4ld.s32 r1, [j];
ld.s32 r2, [k];
add.s32 r3, r1, r2;
st.s32 [i], r3
输入操作数在asm语句之前加载到寄存器中,然后将结果寄存器存储到输出操作数中。”=r”中的”=”修饰符指定写入寄存器,还有”+”修饰符modifier指定寄存器是读和写,例如1
asm("add.s32 %0, %0, %1;":"+r"(i):"r"(j));
多个指令可以组合成一个asm()语句;基本上,任何合法的东西都可以放入asm字符串中。通过使用 C/C++ 的隐式string串联,可以将多个指令拆分到多行中。C++样式行末尾注释“//”和经典的C样式注释“/**/”都可以穿插这些字符串用作注释。template-string要在 PTX 中间文件中生成可读输出,最佳做法是以”\n\t”终止每个指令字符串,但最后一个指令字符串除外。
例如,一个例程可以为1
2
3
4
5
6
7
8
9__device__ int cube(int x)
{
int y;
asm(".reg .u32 t1;\n\t" // temp reg t1
"mul.lo.u32 t1, %1, %1;\n\t" //t1=x*x
"mul.lo.u32 %0, t1, %1;" //y=t1*x
: "=r"(y):"r"(x));
return y;
}
如果输出操作数由 asm 指令有条件地更新,则应使用“+”修饰符。在这种情况下,输出操作数是隐式使用的。例如1
2
3
4
5
6
7
8
9
10
11
12
13__device__ int cond(int x)
{
int y=0;
asm("{\n\t"
".reg .pred %p;\n\t"
"setp.eq.s32 %p,%1,34;\n\t" // x==34?
"@%p mov.s32 %0, 1;\n\t" // set y to 1 if true
"}" // conceptually y=(x==34)?1:y
:"+r"(y):"r"(x));
return y;
}
constraint
每个 PTX 寄存器类型都有一个单独的约束符:1
2
3
4
5"h"= .u16 reg
"r"= .u32 reg
"l"= .u64 reg
"f"= .f32 reg
"d"= .f64 reg
约束“n”可用于具有已知值的即时整数操作数。
例如1
asm("cvt.f32.s64 %0,%1;":"=f"(x):"l"(y));
将会生成1
2
3ld.s64 rdl,[y];
cvt.f32.s64 f1,rd1;
st.f32 [x],f1;
pitfalls
虽然 asm() 语句非常灵活和强大,但你可能会遇到一些陷阱
namespace conflicts
如果在程序中多次调用并内联cube function,则会对临时寄存器t1的重复定义。为了避免这个,需要
- 不要内联cube function
- 在{}中使用’t1’,以便它对每个调用都有单独作用域,即
1
2
3
4
5
6
7
8
9
10
11__device__ int cube(int x)
{
int y;
asm("{\n\t" // use braces for scope
".reg .u32 t1;\n\t" // temp reg t1
"mul.lo.u32 t1, %1, %1;\n\t" //t1=x*x
"mul.lo.u32 %0, t1, %1;" //y=t1*x
"}"
: "=r"(y):"r"(x));
return y;
}
memory space conflicts
由于 asm() 语句无法知道寄存器所在的内存空间,因此用户必须确保使用适当的 PTX 指令。指向 asm() 语句的任何指针参数都作为通用地址传递.
incorrect optimization
编译器假定asm语句除了更改输出操作数之外没有任何作用。要确保在生成PTX期间不会删除或移动asm,应使用volatile关键字.volatile用于告诉编译器,严禁将此处的汇编语句与其它的语句重组合优化。即:原原本本按原来的样子处理这这里的汇编。1
asm volatile("mov.u32 %0, %%clock;"::"=r"(x));
通常,写入的任何内存都将被指定为 out 操作数,但如果对用户内存有隐藏的副作用(例如,通过操作数间接访问内存位置),或者如果要停止在生成 PTX 期间围绕 asm()语句执行的任何内存优化,则可以在第 3 个冒号后添加“memory”clobbers 规范,memory 强制 gcc 编译器假设 RAM 所有内存单元均被汇编指令修改,这样 cpu 中的 registers 和 cache 中已缓存的内存单元中的数据将作废。cpu 将不得不在需要的时候重新读取内存中的数据。这就阻止了 cpu 又将 registers, cache 中的数据用于去优化指令,而避免去访问内存。1
2asm volatile("mov.u32 %0, %%clock;": "=r"(x) :: "memory");
asm ("st.u32 [%0], %1;": "r"(p), "r"(x) :: "memory");
incorrect PTX
编译器前端不解析asm语句模板字符串,也不知道他的含义甚至不确保ptx是否有效。例如1
asm("mov.u32 %0,%n1;":"=r"(n):"r"(1));
“%n1”中的“n”修饰符不受支持,它将传递给 ptxas,其中它可能导致未定义的行为。
error checking
以下是编译器将在 inline PTX asm 上执行的一些错误检查
不允许单个asm操作数只用多个constraint
1
asm("add.s32 %0,%1,%2;":"=r"(i):"rf"(j),"r"(k));
错误:asm 操作数可能只在device/global函数中指定一个constraint字母
只允许标量变量作为asm操作数。特别是不允许使用struct类型变量
1
2int4 i4
asm("add.s32 %0,%1,%2;":"=r"(i4):"r"(j):"r"(k));错误:asm操作数必须是标量
PTX中asm constraint所隐含的类型和大小必须与关联操作数的类型和大小匹配。例如其中ci是char1
asm("add.s32 %0,%1,%2;":"=r"(ci):"r"(j):"r"(k));
错误:asm 操作数类型 size(1) 与约束 “r” 所暗示的类型/大小不匹配
为了在上面的 asm 语句中使用 “char” 类型变量 “ci”、“cj” 和 “ck”,可以使用类似于以下内容的代码段1
2
3inttemp = ci;
asm("add.s32 %0,%1,%2;":"=r"(temp):"r"((int)cj),"r"((int)ck));
ci = temp;
类型不匹配的另一个示例:对于“float”类型变量“fi”,1
asm("add.s32 %0,%1,%2;":"=r"(fi):"r"(j),"r"(k));
错误:asm 操作数类型 size(4) 与约束 “r” 所隐含的类型/大小不匹配
mma.sp with sparse matrix A
本节主要是用于A100上sparse tensor core的研究。
warp-level指令mma.sp,作为mma的变体。
当A是结构化稀疏矩阵时,每行有50%的零值以特定的形状分布时,可以使用mma.sp进行spmm操作。
对于一个 $M\times N\times K$的mma.sp操作,大小为$M\times K$的矩阵A的所有元素会打包进入一个$M\times K / 2$的矩阵中。在A的每行中,用K/2大小的内存来存储非零元(非零元不满K/2的话会进行填充??),同样地有K/2大小的空间来存储元素的映射关系(列索引),这个被称为metadata。
sparse matrix storage
稀疏矩阵A的粒度定义为矩阵行的子块中非零元素数目与该子块中元素总数的比率,其中子块的大小是特定的。例如,$16\times 16$的矩阵,稀疏度是2:4,即矩阵行中所有的4元素的向量(4个连续元素的子块)包含两个零值。子块中所有非零元的索引被存在metadata中。在一组4个连续的线程中,一个或多个线程根据矩阵形状会存储整个group的metadata,这些线程是使用附加的sparsity selector运算符指定的。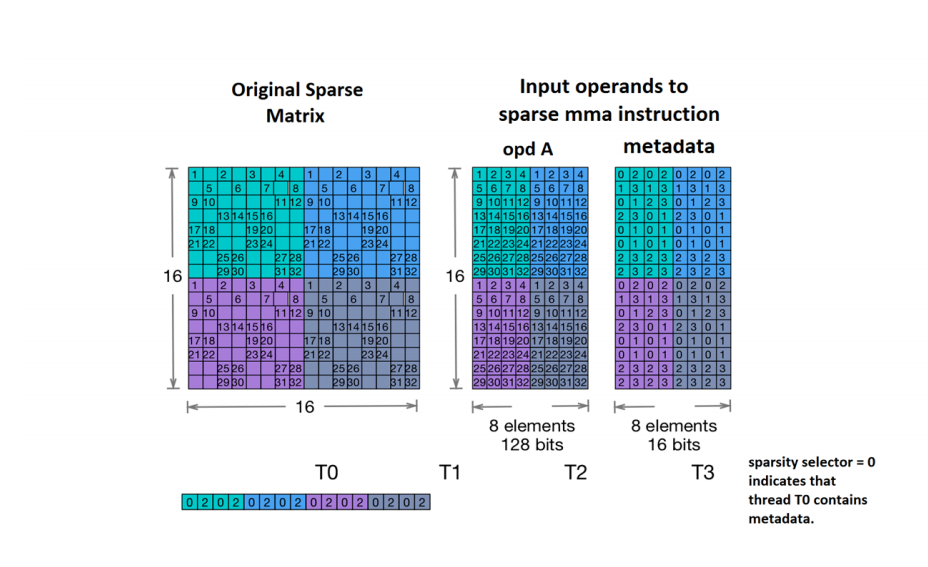
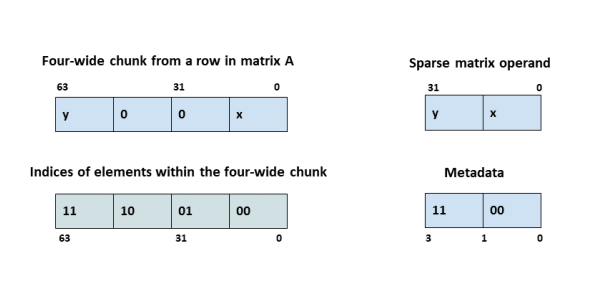
上图表示一个4线程的group负责的sub-chunk,有两个非零元x和y,在mma.sp中元素存在sparse matrix operand,索引存在metadata中(相对列索引)。
不同矩阵形状和数据类型的粒度如下所示
sparse mma.sp with half-precision and .bf16 type
sparsity selector表示哪些线程存储metadata:
- m16n8k16:group中的一个线程存储metadata,在{0,1,2,3}中选择
- m16n8k32: group中的一对线程存储metadata,在{0,1}和{2,3}中各选一个
sparse mma.sp with .tf32 type
当矩阵A的元素类型是.tf32,A的结构化稀疏的粒度必须是1:2。元素存在operand数组中,索引存在matadata中。需要注意的这里还是用4bit来存储索引,只有0b1110和0b0100是有效的索引值,其余索引会产生未定义行为。
这里的块的长度是2,又是1:2的粒度,却不用1bit来存储索引,这里要注意一下。

sparse selector决定哪些线程获得metadata
- m16n8k16:group中的一个线程存储metadata,在{0,1,2,3}中选择
- m16n8k32: group中的一对线程存储metadata,在{0,1}和{2,3}中各选一个
虽然subchunk变成了2,但还是4个线程在协作
sparse mma.sp with integer type
当A和B有1 .u8/.s8的元素类型,矩阵A结构化稀疏的粒度是2:4,和前面的没有差别。
当A和B有1 .u4/.s4的元素类型,矩阵A pair-wise 结构化稀疏的粒度是4:8,这里的限制条件更多了。此时chunk大小是8,对于每两个连续元素组成的子块要么都是零值,要么都是非零值。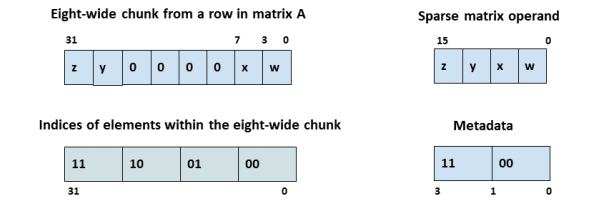
sparse selector为
- m16n8k32 with .u8/.s8 and m16n8k64 with .u4/.s4 type: group中一对线程存储metadata,在{0,1}和{2,3}中各选一个
- m16n8k32 with .u8/.s8 and m16n8k64 with .u4/.s4 type: 一组四个连续线程中的所有线程都提供sparsity metadata。因此,在这种情况下,稀疏性选择器必须为 0。稀疏性选择器的任何其他值都会导致未定义的行为。
matrix fragments for multiply-accumulate operation with sparse matrix A
本节主要描述线程寄存器的上下文与各种矩阵的fragment和sparsity metadata的关联。
- 对于矩阵A,仅根据寄存器向量大小及其与矩阵数据的关联来描述fragment的布局。