动态并行
CUDA的动态并行允许在GPU端直接创建和同步新的GPU内核。在GPU端直接创建工作的能力可以减少在主机和设备之间传输执行控制和数据的需求,因为在设备上执行的线程可以在运行时决定启动配置。
嵌套执行
在动态并行中,内核执行分为两种类型:父母和孩子。父线程、父线程块或父网格启动一个新的网格,即子网格。子线程、子线程块或子网格被父母启动。子网格必须在父线程、父线程块或父网格完成之前完成。只有在所有的子网格都完成之后,父母才会完成。
下图说明了父网格和子网格的使用范围。主机线程配置和启动父网格,父网格配置和启动子网格。在线程创建的所有子网格都完成之后,父网格才会完成。如果调用的线程没有显式同步启动子网格,那么运行时保证父母和孩子之间的隐式同步。下图在父线程中设置了栅栏,从而可以与其子网格显式同步。
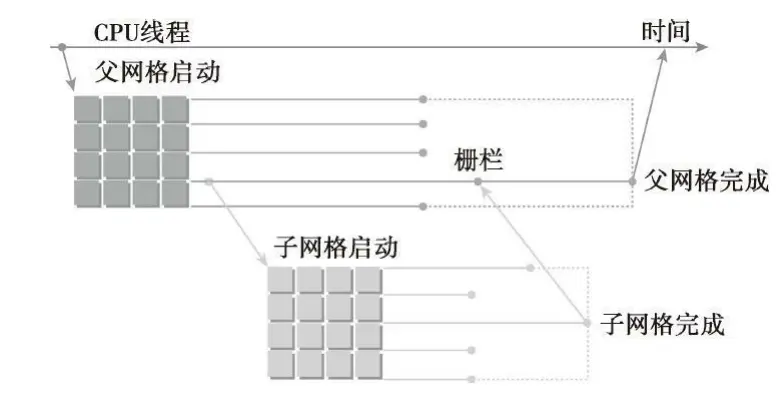
设置栅栏,需要补充
- 设备线程中的网格启动,在线程块间是可见的。在线程块中,只有所有线程创建的子网格完成之后,线程块才结束。如果线程块中的线程在所有网格完成之前退出,那么在那些子网格上隐式同步会被触发。
- 当父母启动一个子网格,父线程块与孩子显式同步之后,孩子才能开始执行。
- 父网格和子网格共享相同的全局和常量内存存储,但他们有不同的局部内存和共享内存。
- 父网格和子网格可以对全局内存并发存取。有两个时刻,子网格和他的父线程见到的内存完全相同:
- 子网格开始时
- 子网格完成时
- 共享内存和局部内存分别于线程块或线程来说是私有的,同时在父母和孩子之间不是可见或一致的。局部内存对线程来说是私有存储,并且对该线程外部不可见。当启动一个子网格时,向局部内存传递一个指针作为参数是无效的。
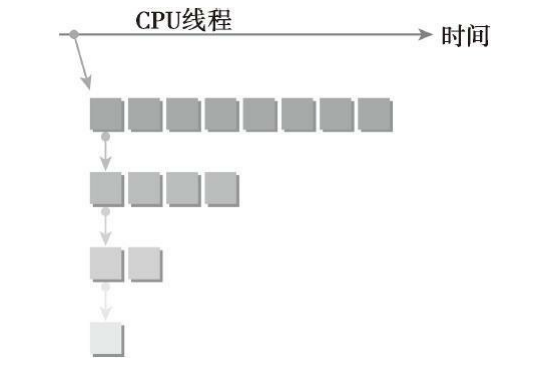
下图表示在GPU上嵌套hello world,每个网格的第0号线程输出hello world。
 |
 |
|---|---|
因为动态并行是由设备运行时库所支持的,所以函数必须在命令行使用 -lcudadevrt 进行明确链接。1
nvcc -arch=sm_35 -rdc=true nestedHelloWorld.cu -o hestHelloWorld -lcudadevrt
当-rdc 标志为true,他强制生成可重定位的设备代码,这是动态并行的一个要求。
动态并行的限制条件
动态并行只有在计算能力为3.5或更高的设备上才能被支持。通过动态并行调用的内核不能在物理方面独立的设备上启动。动态并行的最大嵌套深度限制为24,但实际上,在每一个新的级别中大多数内核受限于设备运行时系统需要的内存数量。因为为了对每个嵌套层中的父网格和子网格之间进行同步管理,设备运行时需要保留额外的内存。